
Les Mécanismes
VMware utilise des mécanismes de gestion intelligents du CPU, de la Mémoire, du Storage et du Réseau pour permettre la cohabitation d’un grand nombre de VMs et l’overcommitting.
Dans cet article je vais me pencher plus particulièrement sur la gestion de la RAM avec des explications claires sur l’utilisation et le fonctionnement des mécanismes :
- Ballooning : Récupération par augmentation de la « pression » du Guest OS
- Transparent Page Sharing (TPS) : Récupération par partage de pages mémoire redondantes
- Zipping : Récupération par compression de pages mémoire
- Swapping (vSwap) : Récupération par utilisation du stockage
Overcommitting
Tout d’abord qu’est-ce que l’Overcommitting, en faisant simple c’est le fait d’utiliser des ressources en excès, assigner plus de RAM aux VMs que l’ESXi n’en possède, on dit alors qu’il y a Contention.
Au premier abord ça parait être une mauvaise chose, risque de Swapping … mais non et je vais vous expliquer pourquoi.
Car en réalité il y a deux manières de procéder et nous allons séparer mémoire, Disponible (ESXi), Assigné (Config. VM) et Utilisé (Guest OS) :
- La Bonne : Assigner plus de RAM aux VMs que disponible sur l’hyperviseur mais vérifier que la quantité totale utilisée ne dépasse pas la quantité disponible.
- La Mauvaise : Assigner plus de RAM aux VMs que disponible sur l’hyperviseur et laisser la quantité totale utilisée dépasser la quantité disponible.
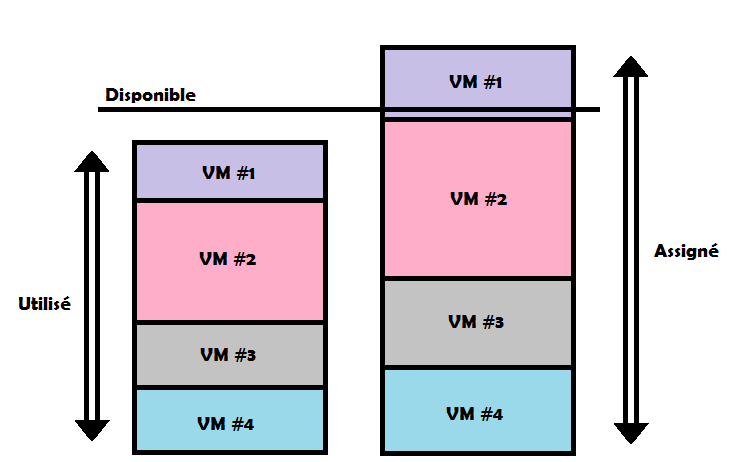
Ainsi vous allez utiliser des mécanismes qui n’affectent pas ou très peu les performances comme le TPS ou le Ballooning. Utiliser l’Overcommitting n’est pas comme on pourrait le croire une mauvaise chose, un risque ou un frein à la performance si bien fait, mais seulement il faut monitorer et savoir ce que l’on fait.
Pour conclure, il n’y a pas de danger ou de risque caché, tant que l’infrastructure est Monitorée et que vous savez/comprenez ce que vous faites. Pour ceci je ne saurais trop vous conseillez d’utiliser l’excellent SexiGraf basé sur Grafana, il vous permet de sortir des graphiques utiles pour les Administrateur VMware, dans notre cas je vous conseille de jeter un coup d’œil à « VMware Multi Cluster Top N VM Overcommit »
ESXi States
Ces différents mécanismes sont utilisés en rapport avec l’état de l’hyperviseur, plus la RAM va venir à manquer, plus sont état va se dégrader et plus les mécanismes vont être utilisés.
PS : Il y a deux limites, mais ce tableau et la pour simplifier la compréhension.
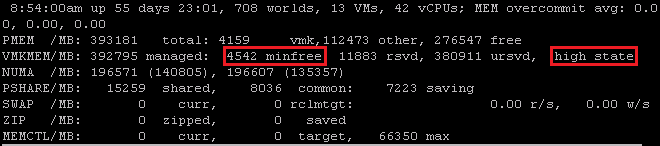
| HIGH (<400% of minFree) | CLEAR (<100% of minFree) | SOFT (<64% of minFree) | HARD (<32% of minFree) | LOW (<16% of minFree) | |
| Sharing | X (Break) | X (Force) | X | X | X |
| Ballooning | X | ||||
| Zipping | X | X | |||
| Swapping | X | X | |||
| Blocking | X |
Le Sharing est activé de base dans tous les états mais il reste une petite subtilité avec les Larges Pages qui fait qu’il n’est pas vraiment utilisé, en tout cas dans vSphere 5, sur vSphere 6 c’est un peu différent et je vous l’explique un peu plus bas.
En High State, l’hyperviseur utilise le Transparent Page Sharing, il va commencer à « casser » les Pages sous la barre des 400%, mais tout ceci est expliqué plus bas.
Une fois que la demande approche la limite Clear State sous la barre des 100% de minFree, les Pages continuent à être cassé et le partage est forcé pour récuperer de la RAM sans affecter les performances.
En Soft State, l’hyperviseur vas commencer à utiliser le Ballooning. L’activation se fait avant la limite car il ne permet pas une récupération rapide de RAM.
Si le Ballooning seul ne suffit pas à récupérer assez de RAM ou si la limite Hard est atteinte, l’hyperviseur va arrêter le Ballooning et commencer le Swapping mais aussi le Zipping car cela va de pair.
Il y a donc en Hard State trois mécanismes activés ensemble, qui devraient permettre de récupérer assez de RAM pour passer en Soft State.
Si vraiment dans de rare cas tout ceci ne suffit pas et que la limite Low State est atteinte … la ça se complique car l’hyperviseur va bloquer l’allocation de nouvelles pages mémoire.
La quantité de minFree et l’état de l’Hyperviseur sont disponibles via ESXTOP.
Ballooning
| HIGH (<400% of minFree) | CLEAR (<100% of minFree) | SOFT (<64% of minFree) | HARD (<32% of minFree) | LOW (<16% of minFree) | |
| Ballooning | X |
Le Ballooning est un des mécanismes innovant qui permet à l’ESXi de réclamer de la RAM aux VMs en cas de manque par Overcommitting.
Une fois l’ESXi en manque de RAM, les VMs ne se rendent pas compte de ceci car elles ne voient que leur propre RAM attribuée, il faut ainsi pouvoir les mettre au courant de ce manque de l’hôte et ainsi leur demander de faire des sacrifices (SWAP) pour le bon fonctionnement de l’infrastructure, tout ceci est rendu possible grâce à l’installation des VMware Tools qui peuvent agir sur le Guest OS par le biais du balloon driver (vmmemctl).
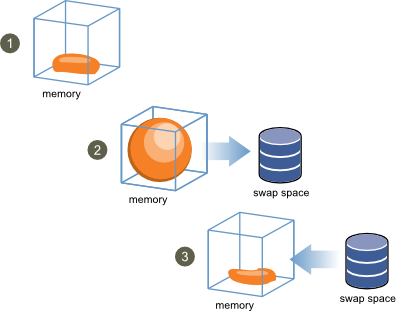
Les tools vont simuler à la manière d’un ballon le manque de RAM en augmentant la pression, le ballon grossis faisant croire une diminution de la quantité de RAM allouée pour permettre à l’ESXi de se l’attribuer. L’OS de la VM va ainsi utiliser ses propres algorithmes de gestion de la mémoire et si nécessaire va swapper, une fois le ballon dégonflé et la pression diminuée l’OS pourra vider son swap et remettre en RAM.
Il est possible de limiter la quantité récupéré sur une VM par le Ballooning avec l’option sched.mem.maxmemctl.
Ci-dessous le cas d’une VM avec Ballooning pour finir sans, on voit clairement que le Granted (Quantité de RAM autorisée) augmente proportionnellement avec la diminution du Ballooning. L’OS va ensuite pouvoir consommer ce surplus de RAM et vider son SWAP et on voit bien qu’il le fait.
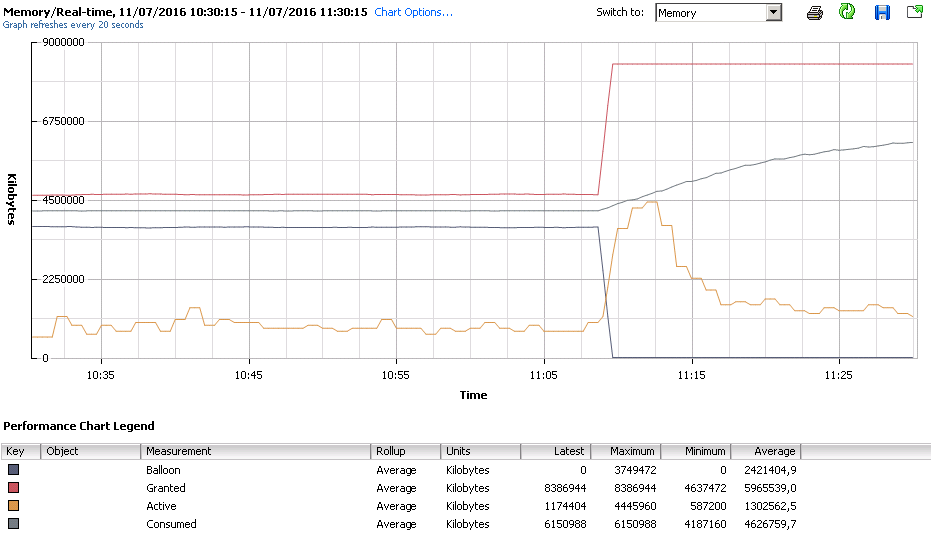
Granted : C’est la limite virtuelle vue par la VM, en temps normal c’est la valeur RAM que vous avez configuré, si il y a ballooning cette valeur vas diminuer pour forcer le Guest OS à swapper.
Consumed : C’est la valeur de consommation réelle, l’espace utilisé sur les barrettes de RAM, en gros Consumed = Granted – TPS + Memory Overhead.
Active : C’est l’utilisation de RAM utilisé par le Guest OS. Cette valeur est une estimation d’après des statistiques, à prendre donc avec des pincettes …
Transparent Page Sharing
| HIGH (<400% of minFree) | CLEAR (<100% of minFree) | SOFT (<64% of minFree) | HARD (<32% of minFree) | LOW (<16% of minFree) | |
| Sharing | X (Break) | X (Force) | X | X | X |
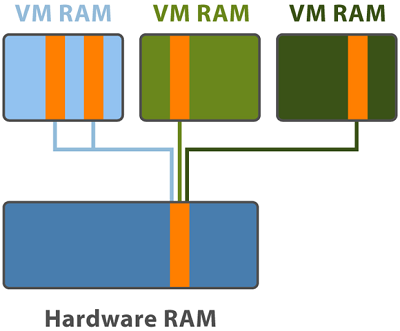
La virtualisation permet de mutualiser des ressources hardwares pour plusieurs OS souvent similaires grâce aux templates et hébergeant les mêmes applicatifs. Cette similitude se retrouve aussi au niveau mémoire, certaine pages seront souvent identiques et prendront chacune leur espace mémoire.
C’est là qu’un autre des mécanismes entre en jeu, le TPS va permettre de partager ces pages mémoire identiques entre les VMs, comme le ferait un lien symbolique vers un fichier. L’hyperviseur va ainsi récupérer les pages redondantes et garder une seule copie qui sera partagée de manière transparente entre les VMs, augmentant ainsi la possibilité d’Overcommitting.
Large Pages
TPS est activé par défaut en inter/intra-vm et ceci dans tous les ESXi States, mais il faut savoir qu’il n’est pas utilisable en inter-vm dans le cas des Large Pages (entre autre), simplement parce qu’il est difficile voire impossible de trouver des pages similaires du fait de leur taille mais aussi parce que la comparaison est bien plus lente à faire que pour des Small Pages.
ESX will not share large physical pages because:
The probability of finding two large pages that are identical is very low.
The overhead of performing a bit-by-bit comparison for a 2MB page is much higher than for a 4KB page.
C’est là qu’on peut se poser des questions, car par défaut l’ESXi va forcer ces Larges Pages, pour des raisons de performances, un peu comme du Jumbo Frame le ferait. Pas de panique, ce n’est pas pour autant qu’ils se tirent une balle dans le pied chez VMware…
Sur vSphere 5 il nous fallait être overcommité et donc dans un état « dégradé » pour vraiment utiliser le TPS car les Larges Pages étaient à ce moment « cassés »
High (100% of minFree), Soft (64% of minFree), Hard (32% of minFree) et Low (16% of minFree).
Sur vSphere 6 un 5e état a fait son apparition et les valeurs MinFree ont été revues. High a été redéfinis (400% of minFree) et Clear a été ajouté (100% of MinFree).
Tout ceci pour commencer à « casser » en Small Pages et permettre à TPS de faire son travail arrivé sous la barre des 400% of minFree et éviter la dégradation de performance des autres états.
Salage
Ça va vous suivez toujours, parce qu’il reste encore une petite partie « sécurité » parce que oui, ils se sont rendu compte qu’il y avait une brèche dans le système avec l’utilisation des Small Pages, ils ont donc inclus une rustine améliorative du chiffrement, le Salage.
Extait Hypervisor.fr
Donc, pour que l’attaque soit réalisable, il faut que la VM de l’attaquant se retrouve, avec la VM de la victime, seules sur le même socket du même ESX et avec le même GuestOS !
Je vous conseille de faire un tour sur le post « The Phucking Salt » qui fait le tour de la question, montrant la perte de performance mais aussi au final les problèmes de sécurité des … Larges Pages.
The Phucking Salt
On commence en mode défaut (Mem.ShareForceSalting=2 et Mem.AllocGuestLargePage=1)
On remarque qu’au 3/4 du bootstorm le premier mécanisme de reclaim est la swap, viennent ensuite la compression, le ballooning et seulement après le sharing (principalement des zéros). Avec 23Go de swap et 43Go de zip, n’espérez pas des temps de réponses de folie même avec du SSD.
On continue sans le salting (Mem.ShareForceSalting=0 et Mem.AllocGuestLargePage=1)
Avec plus de 100Go de sharing et seulement 3,6Go de swap les effets de l’overcommit (3:1 quand même) sont presque imperceptibles dans ce scénario même si on regrette de constater que le swapping est encore le 1er mécanisme à se déclencher.
Résumé TPS
Pour résumer, le TPS est activé par défaut mais n’est pas utilisé à son plein potentiel sur un ESXi qui se balade niveau ressources disponibles, une fois arrivé sous la limite High (400% MinFree) les pages vont être cassés et attendre d’être partagés par TPS, arrivé sous la limite Clear (100% minFree), le TPS va être forcé à casser et partager rapidement. Gardez à l’esprit que le Salage va lui aussi avoir son impact et repousser l’utilisation du TPS.
Je vous conseille dans une infrastructure type Citrix VDI, d’au moins essayer les pages à la demande…
Si on veux absolument utiliser le TPS, on force la désactivation des Larges Pages.
Mem.AllocGuestLargePage=0 (NUMA)
Mem.AllocGuestRemoteLargePage=0 (Non-NUMA)
Pour être cohérent, à ce moment on désactive le Salting forcé.
Mem.ShareForceSalting=0
Par contre si on souhaite avoir un compromis, on peut laisser le Guest OS/l’Application faire une demande de Large Page. Small Pages par défaut mais Large Pages tout de même possible.
LPage.LPageAlwaysTryForNPT=0
Mem.AllocGuestLargePage=1 (NUMA) Mem.AllocGuestRemoteLargePage=1 (Non-NUMA)
Overhead Memory
Vous avez certainement entendu parler d’Overhead, qu’il n’est pas négligeable sur les grosses VMs, qu’à cause de lui il ne faut pas oversizer …
Tout ceci est vrai, mais finalement c’est quoi l’Overhead ?
Il faut savoir que pour fonctionner, l’enveloppe VM à besoin d’une certaine quantité de RAM, utilisée par différent composants comme le Virtual Machine Monitor (VMM), le processus VMX, les périphériques virtuels…
Cette quantité de RAM bien qu’au premier abord négligeable peut devenir conséquente sur des infrastructures de plusieurs milliers de VM, surtout que cet Overhead n’utilise pas les mécanismes de récupération de RAM, mais peux utiliser par contre un fichier swap (VMX Swap)
Echantillon d’Overheads par VM avec VMX Swap activé (Par défaut)
| RAM (MB) | 1 vCPU | 2 vCPU | 4 vCPU | 8 vCPU |
| 256 MB | 20.29 | 24.28 | 32.23 | 48.16 |
| 1024 MB | 25.90 | 29.91 | 37.86 | 53.82 |
| 4096 MB | 48.64 | 53.72 | 60.67 | 76.78 |
| 16384 MB | 139.62 | 143.98 | 151.93 | 168.60 |
Swapping / Zipping
| HIGH (<400% of minFree) | CLEAR (<100% of minFree) | SOFT (<64% of minFree) | HARD (<32% of minFree) | LOW (<16% of minFree) | |
| SW / ZP |
X | X |
Le Swapping et le Zipping étant utilisés ensemble, j’ai décidé de les regrouper pour en parler. Ces mécanismes vont être utilisés dans le cas où le Balooning et le Sharing n’ont pas suffis à récupérer assez de RAM.
Ici rien de bien compliqué, c’est un mécanisme connu sur les OS, les pages en RAM sont transférés dans un fichier swap (.vswp) sur le Storage. Les conséquences sont bien connues, une réduction draconiennes des performances, et oui la RAM reste ce qu’il y a de plus rapide, même si les SSD aident, le Swapping reste le dernier recourt à éviter.
A savoir que le fichier Swap VMware (.vswp) est égal au montant de la RAM alloué. Si vous avez 4GB de RAM, vous aurez un fichier .vswp de 4GB, ce qui n’est pas négligeable sur le Storage.
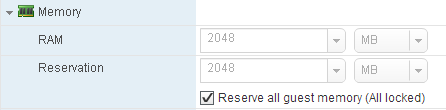
.vswp = Mémoire Allouée – Memoire Reservée
Ce fichier ne se supprime pas, par contre il est possible de diminuer sa taille voir de le vider completement en reservant la RAM dans le paramètres de la VM (Reserve all guest memory (All locked))
Prise en compte par redémarrage
Cas spécifique
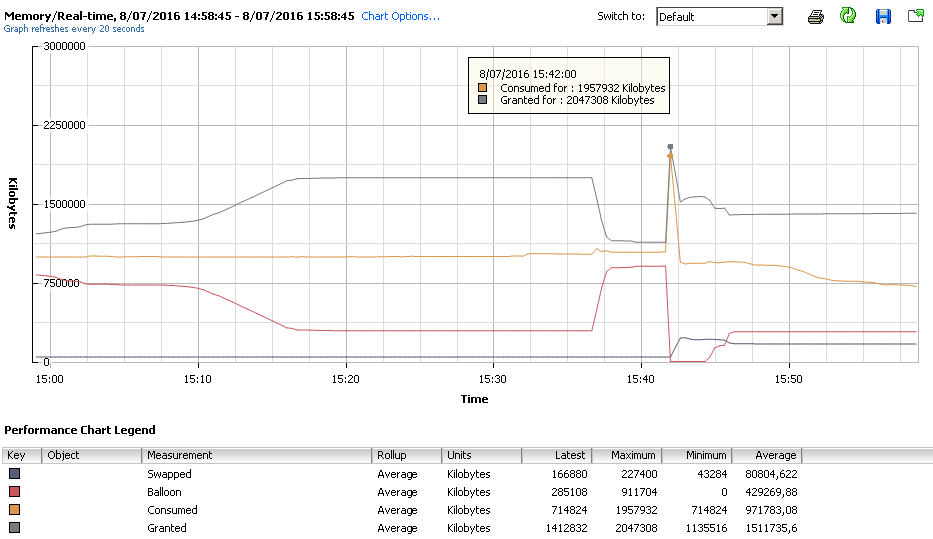
Pour en revenir au début où je vous disais qu’en High State donc avec une quantité de RAM libre suffisante, on pouvait malgré tout avoir des mécanismes qui entrent en jeu.
Ci-dessous le graphique d’une VM sur un ESXi en High State, on voit clairement que jusqu’à 15h40 il y a du Ballooning et du Swapping. Ceci vient du fait que dans les ressources de la VM, une limite a été mise et bride/réclame donc comme un ESXi en Hard State le ferait.
C’est là qu’il faut faire attention avec les Ressource Pools, les Réservations et les Limites.
Car vers 15h40 une mise à jour des VMware Tools a été faite. Au moment de la désinstallation, le driver de Ballooning absent et la consommation n’étant plus retenue par la pression, elle s’est envolée jusqu’à la limite Granted, l’ESXi s’est emballé et a swappé. Au moment du swap une grosse perte de performance s’est faite sentir jusqu’à freezer quelques secondes l’OS.
Conseils
- Installer et maintenir à jour les VMware Tools, ils sont utiles pour une meilleur gestion de la VM mais aussi pour le Ballooning.
- Configurer les Limites, les Réservations et les Ressources Pools avec soin, si les valeurs ne sont pas appropriés et elles peuvent le devenir à force, vous allez vous retrouver avec du Ballooning voir pire du Swapping inutile.
- TPS et Overcommitting sont bon mangez en, plus sérieusement apprenez à bien les utiliser.
- Gardez en tête, Monitoring is my friend ! Il va vous permettre de gérer votre Overcommitting comme un dieu et éviter les mauvaise surprise et le Swapping …
- Never Oversize, si votre OS et ses applicatif n’utilisent pas plusieurs vCPU ou ne consomment pas beaucoup de RAM, n’abusez pas avec les specs … Overhead is watching you !
- Dans une infrastructure type VDI, activer les Large Pages on Demand.
 2 vote(s)
2 vote(s)






Super Post !!!! Keep going
Drop moi un petit mail, j’ai aussi un blog vroomblog.com
Bonjour,
Je trouve vraiment utile et clair ton post.
Par contre quand tu dis :
Consumed : C’est la valeur de consommation réelle, l’espace utilisé sur les barrettes de RAM, en gros Consumed = Granted – TPS + Memory Overhead.
On parle bien de ka consommation réelle SUR l’ESXi ? donc l’espace utilisé SUR les barrettes de RAM de l’ESXi ? c’est bien ca ?
Merci
Bonjour Alex, Mes affirmations sont le fruit de tests et de recherches, je suis ouvert à tout commentaire mais c’est comme ça que je l’analyse. « Consumed » est la consommation réelle sur les barrettes de RAM physiques, c’est une globalité qui inclus l’Overhead de la VM (Service Console, VMkernel ..) Contrairement à la valeur « Active » qui elle est la valeur de consommation du Guest OS, car ce n’est pas parce que 8GB de RAM sont configurés que 8GB vont être totalement consommés par l’OS. Attention toutefois à cette valeur qui n’est pas forcément réelle, c’est une valeur calculée d’après des statistiques, donc à prendre avec des pincettes…
Re-Bonjour,
J’ai une autre question concernant le ballooning.
Sur ton graphe de ballooning on voit comme valeur max 3749472 Ko mais à quoi cela correspond t il ? A la valeur que lui réclame l’ESXi ou à la valeur que lui fournit l’ESXi après avoir récupérer cette quantité sur d’autres VMs.
Merci
Hello,
C’est la valeur de pression du Ballooning, donc effectivement la valeur que l’ESXi réclame à la VM en lui faisant croire qu’il manque cette quantité de RAM physiquement.
D’ailleurs on le voit bien avec le Granted :
8386944 (Max Granted) – 3749472 (Max Balloon) = 4637472 (Min Granted)
Cordialement,
[…] d’un grand nombre de VMs et l’overcommitting. Après avoir parlé de la RAM dans l’article VMware – Les mécanismes de gestion de la RAM, je vais me pencher aujourd’hui sur la gestion du CPU avec des explications claires sur […]