
Synopsis
Je me lance aujourd’hui dans un nouveau type de post style « Best Practice » sur Numa & vNuma, il vont permettre de comprendre en détail une fonctionnalité et ainsi éviter des erreurs liées au design, au choix du matériel voir de débattre.
Pour cette nouvelle aventure de virtualisation je débute avec Numa et vNuma, histoire d’éclaircir les interrogations sur ce mot barbare.
Définition
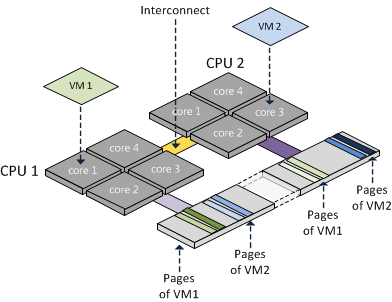
Numa pour Non-Uniform Memory Access est une architecture matérielle, c’est-à-dire que le serveur physique ou plus particulièrement la liaison physique entre la RAM et le CPU qui a évoluée.
Avant cette évolution, la liaison était généralement de type UMA (Uniform Memory Access), c’est une architecture mémoire partagée entre les multiples CPU du serveur physique via un contrôleur mémoire (MCH), il y a donc des limitations d’évolution, de bande passante et de latences.
frankdenneman.nl
Pour pallier à ces facteurs limitants, les ingénieurs ont fait évoluer le hardware vers une du Numa, ils ont ainsi supprimé la topologie centralisée via contrôleur mémoire.
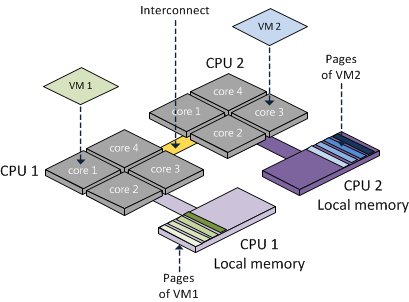
En Numa la mémoire est directement liée à son CPU, on se retrouve ainsi avec une mémoire dite « Local » et « Remote » pour celle liée à un autre CPU.
Vous l’aurez compris, la mémoire dite « Local » sera la plus performante, l’utilisation de la mémoire « Remote » obligeant l’utilisation du pont d’interconnexion entre les CPU.
frankdenneman.nl
L’architecture physique évoluant, les ingénieurs VMware se sont ainsi adapté et l’ESXi est devenu Numa Aware, pour ainsi se rendre compte de cette architecture et l’utiliser le mieux possible.
vNuma se résumé au Numa Aware mais coté VM, cela permet au Guest OS d’être conscient qu’il se trouve sur une architecture Numa et ainsi gérer au mieux sa répartition de RAM.
Avec la plupart des CPU on peut corréler 1 CPU = X Cores Physique = 1 Numa Node.
Toutefois certains CPU « 12-cores » sont deux « 6-cores » aggrégés, ce qui engendre deux Numa Nodes sur un seul CPU : 1 CPU = 2x X Cores Physique = 2 Numa Nodes.
On se retrouve donc à dire Cores physique par Numa Nodes pour être précis…
Scheduler NUMA
Au démarrage d’une VM, si celle-ci à un nombre de vCPU plus petit ou égal au nombre de Cores d’un node, le Numa Scheduler va assigner un node par défaut et lui assigner le plus possible de mémoire locale. En revanche si le nombre de vCPU dépasse (Wide-VM), elle va être séparée sur plusieurs nodes avec un risque d’avoir du remote.
Cependant il peut arriver dans certains cas comme un grand nombre de VM, qu’il ne soit pas possible de mettre tout en local. Dans le cas où plus de 20% est en remote, le scheduler va essayer de changer de Numa Node pour améliorer le ratio. La gestion Numa est donc complètement automatisée, par contre dans le cas où l’administrateur souhaite gérer en manuel il y a l’option avancée numa.nodeAffinity.
Quand vous spécifiez une « Numa Node Affinity », le scheduler Numa est toujours en charge de la gestion de localité, par contre avec une affinité CPU ce n’est pas le cas, d’ailleurs je vous déconseille fortement d’en mettre…
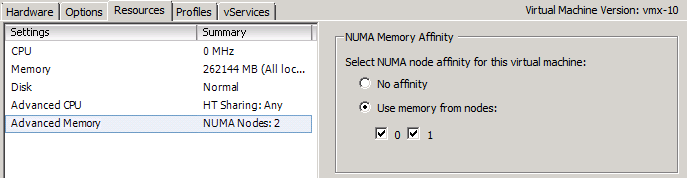
ESXTOP
Cas pratique avec un ESXTOP, on se place en affichage Mémoire (m), on modifie les champs (f) pour choisir le Nom (d) et les Stats Numa (g) puis on passe en affichage VM (V)
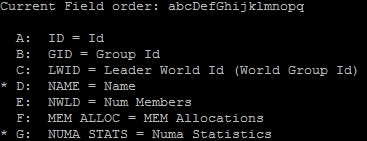
On se retrouve donc avec deux Numa Nodes (Rouge), ayant 2 CPU et 524GB. Le split est bon avec environ 262GB de RAM par Node.
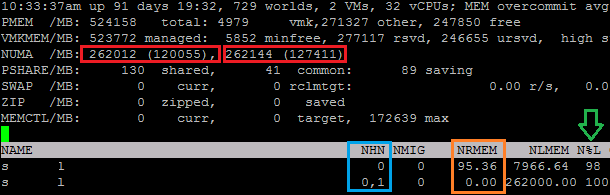
Dans mon cas j’ai deux VM, la première utilisant le Numa Node 0 (NHN) et 98% en local (N%L) soit 95.36MB en Remote (NRMEM). La deuxième quand a elle est parfaitement bien séparée entre les deux Numa Nodes et utilise 100% en Local, donc 50% sur le CPU0 et 50% sur le CPU1.
vNuma
vNuma est très utile si vous utilisez des Wide-VM, il va permettre de mitiger les latences mémoire en prenant part dans la gestion Numa de l’ESXi, son utilisation requière au minimum la VM Version 8 et 8 vCPU (Par défaut).
La topologie vNuma affichée à la VM est set au premier démarrage et ne change pas jusqu’à modification du nombre de vCPU, voilà pourquoi il est conseillé d’avoir des hosts dans le cluster ayant la même topologie Numa, les performances ne seront donc pas dégradées suite à un vMotion.
Advanced Settings
Vous pouvez être amené à vouloir spliter une VM sur plusieurs Numa Nodes, si vous souhaitez privilégier la bande passante à la latence il peut être utile de limiter le nombre de vCPU par node.
maxPerMachineNode
Sur des serveurs utilisant l’HyperThreading avec des VM configurés avec plus de vCPU que de Core Numa mais moins que de Cores logique, il peut être bénéfique d’utiliser le core logique avec mémoire local que physique avec mémoire remote.
numa.vcpu.preferHT
vNuma est activé de base pour les VM de plus de 8 vCPU, il peut être utile de revoir cette valeur à la baisse sur des serveur ayant des CPU de moins de 8 Cores physique.
numa.vcpu.min
Design VM
Essayez de sizer vos VMs pour qu’elles s’alignent sur Numa, c’est-à-dire qu’avec un host de 6 Cores physique on va utiliser des multiple de 6 (6, 12, 18, 24 … vCPU)
Quand vous choisissez le nombre de vCPU d’une VM, vous avez le choix entre nombre de Sockets et de Cores. A part pour des raison de licensing, il est fortement conseillé d’utiliser seulement les Sockets et de laisser les Cores à 1.
Il a été prouvé que les performances sont dégradés, surtout dans le cas de Wide-VM. Dans ce cas essayez de déterminer la configuration que vNuma aurait associé à votre VM.
Ex. VM de 16 vCPU sur un serveur de CPUs ayant 10 Cores physique, 2 Sockets & 8 Cores est le plus logique dans ce cas.
Core vs Socket
Exemple sur un serveur avec 4 sockets physiques de 12 cores, soit un total de 48 logical cores sans HyperThreading.
24 sockets/1 core per socket
La machine virtuelle étant configurés avec 24 Logical CPU, vNuma va automatiquement crée la meilleure topologie pour gérer ces 24 cores, soit 4 NUMA nodes.
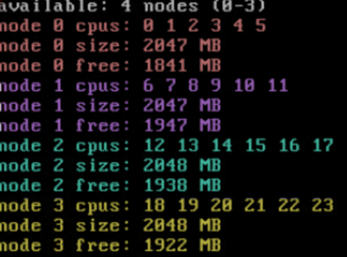
Le benchmark s’est exécuté en 45 secondes.
![]()
2 sockets/12 cores per socket
Toujours le même nombre de Logical CPU, mais cette fois splitté sur 2 Sockets et donc 12 Cores. Étant donné le split forcé sur 2 Sockets, vNuma ne va pas automatiquement créer la bonne topologie, il est ainsi forcé sur 2 NUMA nodes.
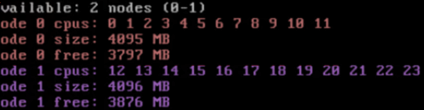
Le benchmark s’est exécuté en 54 secondes.
![]()
1 socket/24 cores per socket
Toujours le même nombre de Logical CPU, mais cette fois sur un 1 Socket et donc 24 Cores. Étant donné la configuration sur 1 Socket, vNuma ne va pas automatiquement créer la bonne topologie, il est ainsi forcé sur 1 NUMA node.

Le benchmark s’est exécuté en 65 secondes.
![]()
Conclusion
Ce test démontre bien que le changement de la configuration des Sockets/Core a un impact sur les performance de la VM, la faute à la topologie NUMA qui n’est pas optimale car non gérée automatiquement par l’ESXi.
Optimisation RAM
En construction, grosse partie à venir …
Le dernier point concernant Numa est la gestion de la RAM au niveau des slots physique.
Quand on parle de modules RAM, il faut prendre en compte deux aspects, la latence et la bande passante qui sont impactés suivant la topologie choisie entre Fréquence, Quantité, Régions et Canaux.
Ce qu’il faut prendre en compte est que plus il y a de DIMM par canal, plus la fréquence diminue et plus la latence augmente. Pour des raisons de scalabilité, blinder de RAM le serveur n’est pas non plus une bonne idée, voilà pourquoi il vaut mieux partir sur un serveur à moitié remplis avec de plus grosses barrettes qu’un full avec des petites.
| DIMM Type | 1 DPC | 2 DPC | 3 DPC |
| 1R RDIMM | 2133 MHz | 1866 MHz | 1600 MHz |
Conseils
- Utiliser/configurer vNUMA pour les Wide-VM.
- Sizer les Wide-VM pour s’aligner sur Numa.
- Améliorer la répartition des modules RAM.
- Utiliser le plus possible les Sockets et non les Cores (vCPU)
- Utiliser ESXTOP, mais ça vous le savez déjà …
http://frankdenneman.nl/2015/02/18/memory-configuration-scalability-blog-series/
 4 vote(s)
4 vote(s)






Merci pour ces explications très enrichissantes
C’est quoi le benchmark que tu as utilisé ?